Attention Tensor Parallel
¶普通的Attention

¶Tensor Parallel Attention
TP size = 4
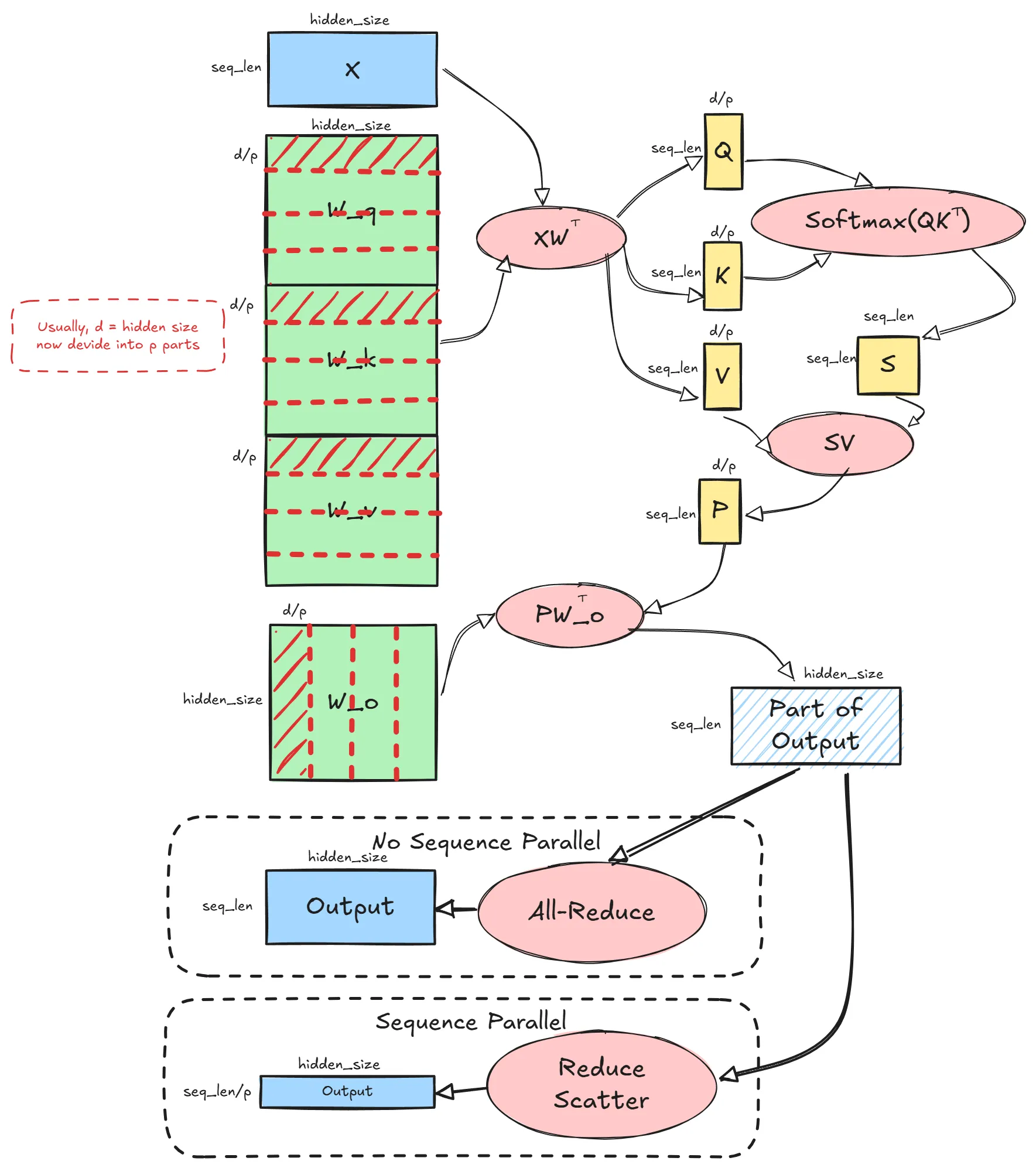
Linear_QKV的out_channel变成dim / tp_size, Linear_out 的 in_channel变成dim / tp_size,out_channel还是hidden_size,最后输出的shape是[seq_len, hidden_size], 因为Linear_out 切的是“累加维度”,所以需要All-Reduce加起来是完整的output
¶Sequence Parallel

All-Reduce = Reduce-Scatter + All-Gather 。 通信量一样
Reduce-Scatter 后,每个卡都有部分sequce,但是已经累加好了,此时可以进行sequence并行计算add, layernorm等。算好后再All-Gather,使每个卡都持有完整的结果,进入下一layer的attention或者MLP
MLP的Tensor parallel 的输入输出和Attention一样,都是完整的输入,输出需要累加

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 JMY Space!
 wechat
wechat- alipay



